This has been a weird week. Grad school seems to go in waves: first I feel really stupid and like I understand nothing, and then suddenly I’m on top of everything. Up until now, this rollercoaster has been out of sync in all of my classes, but this week I’ve been on top of everything. I wonder how long it will last. I even understand what we’re doing in analysis (intro to functional analysis), though that will probably change when we start with abstract measure theory next week…
Update: It did not change when we did abstract measure theory. Shocking, I know. I found the abstract stuff so much easier to do than the concrete Lebesgue measure. When we did abstract measure theory, I didn’t get confused by all the things I do know about the real numbers and I could focus on just understanding measures on sets, rather than mixing in all the weird things that happen with real numbers. Much more fun.
I have a vague recollection of promising a post on the topic of my conference presentation, so here it goes. First of all, you need to know what a knot is. A normal knot, that you tie your shoes with, is not mathematically interesting. It can be tied, so it can (mathematically at least) be untied. Instead, to define a mathematical knot we tie a knot in a piece of string, and connect the ends. That’s the intuitive definition. There are some tweaks to make it behave nicely, but you get the general idea. A link is a knot with several components.
The title of this post mentions link diagrams. We can find a link diagram of a link by simply projecting the link “nicely” onto the plane. I’m fudging a lot of the details about knots, because they are not the main topic here. I might do a post later on knots where I explain all the details properly. Here “nicely” should be taken to mean that one can recover the original knot from the projection.
Now that we have a vague idea what a link diagram is, we define a ribbon graph. A ribbon graph  is a collection
is a collection  of discs called vertices, and a collection
of discs called vertices, and a collection  of discs called edges. The edge discs intersect exactly two vertex discs along an arc on each vertex, and no edges intersect. An easier way to think about a ribbon graph is as a graph embedded in a surface, and then we cut out a thin neighbourhood around the graph to obtain a ribbon graph.
of discs called edges. The edge discs intersect exactly two vertex discs along an arc on each vertex, and no edges intersect. An easier way to think about a ribbon graph is as a graph embedded in a surface, and then we cut out a thin neighbourhood around the graph to obtain a ribbon graph.
Next, I’m going to tell you how ribbon graphs are connected to link diagrams. We take a link diagram, and eliminate each crossing just like when constructing a knot polynomial, choosing a negative or a positive splicing at each crossing. We can choose whichever of the two ways to eliminate each splicing we like. When all the crossings have been eliminated, we are left with a number of disjoint circles. These will be the vertices of our ribbon graph. Connect the vertices where there were crossings with edge discs, and you will end up with a ribbon graph. Since we could choose any splicing we for each crossing, there are up to  possible ribbon graphs associated with each link diagram.
possible ribbon graphs associated with each link diagram.
The natural questions to ask is then: how are these connected? What can we say about the ribbon graphs of a given link diagram? If two link diagrams have the same set of ribbon graphs associated with them, how are the link diagrams related?
My undergraduate advisor already answered both of those questions for links in  . It turns out that the ribbon graphs arising from the same link diagram are partial duals of each other. For the second question, it turns out that the link diagrams are related by a very simple “flip” move. In my undergraduate thesis, I proved that the same results holds for checkerboard-colourable link diagrams of links in
. It turns out that the ribbon graphs arising from the same link diagram are partial duals of each other. For the second question, it turns out that the link diagrams are related by a very simple “flip” move. In my undergraduate thesis, I proved that the same results holds for checkerboard-colourable link diagrams of links in  . This is roughly what I presented at the conference a few weeks ago, to a room full of grad students. Here is a link to the paper on ArXiV.
. This is roughly what I presented at the conference a few weeks ago, to a room full of grad students. Here is a link to the paper on ArXiV.
It was a very nice conference, by grad students, for grad students. The organizers did a really good job putting it together, and there were a lot of interesting people there. It was all very friendly, in part I think because we are all so early in our careers. There were none of the “let me interrupt to talk about why my research is superior disguised as a question for 10 minutes”, which was nice. I also saw quite a few interesting talks, in particular one on the Erdös-Ko-Rado conjecture that I might try to turn into a blog post on a later date. No promises though, since apparently things keep popping up that keep me from blogging for weeks at a time. It should be easier for me to write regularly now that term is over, but no promises on the topics.










 and
and 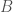 . The question Hall’s marriage theorem answers is: what condition(s) on
. The question Hall’s marriage theorem answers is: what condition(s) on 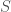 , a subset of say A, we must have that |S| is at most equal to the number of neighbours of the vertices of S, denoted N(S). It turns out that this criteria is also sufficient. I’m going to present my favourite inductive proof of this theorem (all credit to Graph Theory by Reinhard Diestel).
, a subset of say A, we must have that |S| is at most equal to the number of neighbours of the vertices of S, denoted N(S). It turns out that this criteria is also sufficient. I’m going to present my favourite inductive proof of this theorem (all credit to Graph Theory by Reinhard Diestel).
 , we have
, we have  .
. , and assume that the marriage condition is sufficient for the existence of a matching of A whenever |A| is smaller.
, and assume that the marriage condition is sufficient for the existence of a matching of A whenever |A| is smaller. for every non-empty set
for every non-empty set  , we pick an edge
, we pick an edge  and consider the graph
and consider the graph  . Then every non-empty set
. Then every non-empty set  satisfies:
satisfies: . Together with the edge ab, this constitutes a matching of G.
. Together with the edge ab, this constitutes a matching of G.![G' = G[A' \cup B']](https://s0.wp.com/latex.php?latex=G%27+%3D+G%5BA%27+%5Ccup+B%27%5D&bg=fff&fg=444444&s=0&c=20201002) contains a matching of A’. But G\G’ satisfies the marriage condition too. So by the inductive hypothesis, G\G’ contains a matching of A\A’. Putting the two matchings together, we obtain a matching of A in G. Q.E.D.
contains a matching of A’. But G\G’ satisfies the marriage condition too. So by the inductive hypothesis, G\G’ contains a matching of A\A’. Putting the two matchings together, we obtain a matching of A in G. Q.E.D.
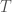 fix a vertex called the root, r, of the tree. Next, we define a partial order on the vertex set of G by
fix a vertex called the root, r, of the tree. Next, we define a partial order on the vertex set of G by  if x is in the unique path from r to y. This is the partial tree-order associated with r.
if x is in the unique path from r to y. This is the partial tree-order associated with r. , which is its own normal spanning tree. Now suppose every graph on n edges has a normal spanning tree. Then there are three cases for the inductive step: if we add another vertex, then the new normal spanning tree will be the old one joined with the new edge. Since there are no more edges connected to the new edge, this is still a normal spanning tree.
, which is its own normal spanning tree. Now suppose every graph on n edges has a normal spanning tree. Then there are three cases for the inductive step: if we add another vertex, then the new normal spanning tree will be the old one joined with the new edge. Since there are no more edges connected to the new edge, this is still a normal spanning tree.


 , of degree 5. Now consider the graph
, of degree 5. Now consider the graph  , obtained by removing vertex
, obtained by removing vertex  (in cyclic order around
(in cyclic order around  . Consider the subgraph
. Consider the subgraph  containing only the vertices coloured by
containing only the vertices coloured by 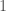 or
or  . Either
. Either  and
and  are in different components, or they are in the same component. If they are in different components, then the colouring of say the component containing
are in different components, or they are in the same component. If they are in different components, then the colouring of say the component containing  . By a similar argument, vertices
. By a similar argument, vertices  and
and  must be connected by a path coloured only with colours 2 and 4. However, since the vertices were labeled cyclically, this path must intersect the one between
must be connected by a path coloured only with colours 2 and 4. However, since the vertices were labeled cyclically, this path must intersect the one between  . This was proven true by Ringel and Young in 1968, with one exception. I’ll talk more about this in my next math post.
. This was proven true by Ringel and Young in 1968, with one exception. I’ll talk more about this in my next math post.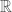 has a convergent subsequence. So there is a subset with some type of structure.
has a convergent subsequence. So there is a subset with some type of structure. is the smallest positive integer such that any two-colouring of the edges of
is the smallest positive integer such that any two-colouring of the edges of  contains a monochromatic red
contains a monochromatic red  or a monochromatic blue
or a monochromatic blue  . To see how this works, I suggest you try to colour the edges of a
. To see how this works, I suggest you try to colour the edges of a  such that there is no monochromatic triangle (
such that there is no monochromatic triangle ( ).
). . First, see the picture below for a colouring of
. First, see the picture below for a colouring of  with no monochromatic triangle. From this we deduce that
with no monochromatic triangle. From this we deduce that  .
.
 . Now, we look at the edges connecting the vertices
. Now, we look at the edges connecting the vertices 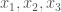 . There are three of them and either all of them are blue, in which case we have a monochromatic blue triangle, or at least one of them is red, We assume that the edge
. There are three of them and either all of them are blue, in which case we have a monochromatic blue triangle, or at least one of them is red, We assume that the edge  is red. Then we have that the triangle
is red. Then we have that the triangle  is monochromatic red. Hence we always have a monochromatic triangle in any colouring of
is monochromatic red. Hence we always have a monochromatic triangle in any colouring of  .
. . To do this, we will assume that
. To do this, we will assume that  .
. must contain either a red
must contain either a red 